- Difficulty level: intermediate
- Time need to lean: 30 minutes or less
- Key points:
- Tasks are defined by
taskstatement as part of substeps - Tasks are executed independently of SoS process and can be executed on remote hosts, even if the host does not share file systems with local host
- Tasks are defined by
Tasks are part of SoS substeps that are encapsulated and executed independently of the main workflow, possibly on remote hosts and cluster systems.
The idea behind tasks is that a workflow can contain a variety of substeps (scripts etc). Some of them are light weight and can be executed together with the workflow (on a local laptop or desktop), and some can be computational or resource intensive and have to be executed on the cluster, or have to be executed on specific remote hosts due to unavailablity of software or data.
Whereas traditional workflow systems require all pieces of workflows to be executed on the same host, SoS allows you to send pieces of workflow to remote hosts, collect their results, and continue. This is achieved through a task mechanism.
Technically speaking, a substep consists of everything after the input statement. It can be repeated with subsets of input files or parameters defined by input options group_by or for_each. For example, if bam_files is a list of bam files,
[10]
input: bam_files, group_by=1
output: f"{_input}.bai"
print(f'Indexing {_input}')
run: expand=True
samtools index {_input}
execute a shell script to process each bam file. This is done sequentially for each input file, and is performed by SoS.
You can easily specify part or all of a step process as tasks, by prepending the statements with a task keyword:
[10]
input: bam_files, group_by=1
output: f"{_input}.bai"
print(f'Indexing {_input}')
task:
run: expand=True
samtools index {_input}
This statement declares the rest of the step process as a task. For each input file, a task will be created with an ID determined from task content and context (input and output files, variables etc).
A queue is needed to execute a task
The task statement will be ignored if no task queue is specified, either from command line with option -q or option queue of the task statement.
Tasks need to be submitted to a task queue to be executed. If you do not specify queue, the task statement will be ignored.
If you do not have anything defined in ~/.sos/hosts.yml (see host configuration for details), a localhost task queue will be available to you. Technically speaking this is a process queue with a maximum of 10 concurrent jobs. To submit the task to this queue, you can specify it as the queue option of task statement.
As you can see, two tasks are generated from two substeps. The tasks have different IDs (because they have different value for variable i) and are executed successfully on localhost.
A more convenient way to specify task queue is to use the -q option of command sos run (or magic %run, %sosrun, or %runfile) as follows:
The differences between these two methods are that
- Task queue specified by option
-qis applied to all tasks defined in the workflow - If both
-qand optionqueueare specified, task queue specified by optionququewill be used for specific tasks.
That is to say, you should generally use -q to send tasks to different task queue, and use queue for tasks that are designed for specified queues.
Under the hood, two task files are created under ~/.sos/tasks (e.g. 4fe780b5245b9e7b.task) and SoS executes commands such as sos execute 4fe780b5245b9e7b to execute them, and collect result from the tasks. This is why you cannot see the output from the echo "I am task {i}" command executed by the tasks.
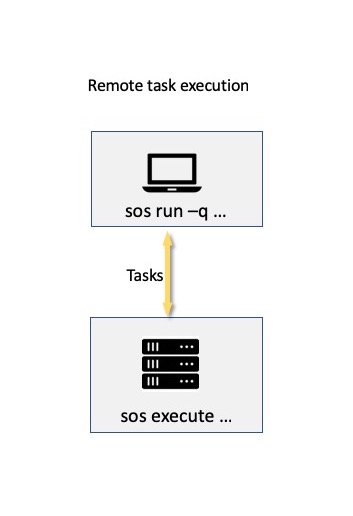
A process queue, like a localhost, execute the task directly, subject to the number of concurrent tasks. If you have a properly configured remote host (namely, have public-key authentication, have SoS installed, specified its address, paths etc in hosts configuration), you can send tasks to the remote host for execution.
More specifically, with the following example, SoS
- Creates a task with an unique ID (
c600532cd99c02c2) determined by the content of the task. - Copy the task file to remote host, translating
inputandoutputpaths if two systems have different file systems. - Execute the task by executing something like
ssh host "bash --login -c sos execute c600532cd99c02c2"
- Monitor the status of the task and update the status in the notebook.
SoS assumes that all input and output files are available with the same pathname on local and remote hosts. In practive, this means that both local and remote hosts should mount the same (NFS) volumes from a file server, or the one host should export drives for the remote hosts to mount. The remote task, however, can use disks (e.g. scratch diskspaces) that are unavailable on local hosts.
A host definition file (usually ~/.sos/hosts.yml) could have the following shared definitions (incomplete)
localhost: office
hosts:
office:
shared:
data: /mount/data
project: /mount/project
cluster:
shared:
data: /mount/data
project: /mount/project
scratch: /mount/scratch
In this configuration, the scripts that are executed on remote server cluster should have input and output files on /mount/data or /mount/project. The task can write to /mount/scratch as long as the content is not referred by the workflow from the office side.
NOTE: SoS currently does not check if all input and output files are on shared drives so the definition of these shared drives are not mandatary. This could change in the future so the specification of shared drives are recommended.
So with a host definition similar to the following
hosts:
bcb:
address: bcbdesktop.mdanderson.edu
max_running_jobs: 100
paths:
home: /Users/{user_name}/scratch
I can submit a task with a R script to be executed on bcb
The output file is available locally after the completion of the task.
Difference between options -q and -r
If you have seen a similar example in remote execution of workflows, you will find that option -r and -q are similar in that they send the R script to remote host for execution. There are however a few key differences:
- Option
-rexecute the entire workflows on remote host while option-qonly part of substeps. In particular, option-rstarts one `sos run` process on remote host and option-qstarts twosos executeprocesses on the remote host. - Option
-ruses input files on remote host and leaves output files on remote host. Option-qcopies input files from local to remote host, and copies output files from remote to local host after the tasks are completed.
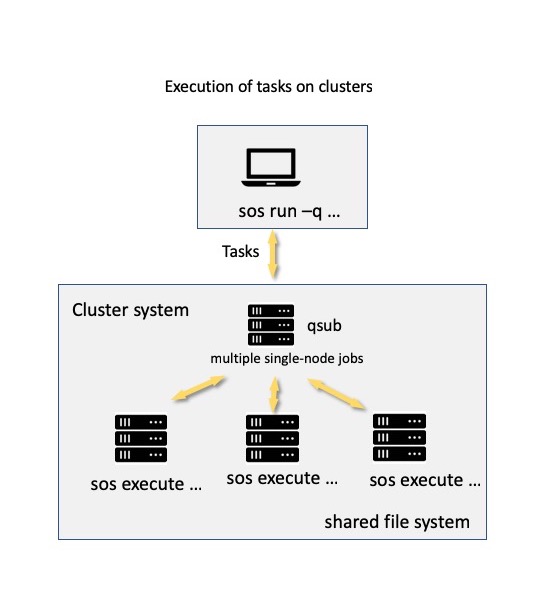
A server can also be a pbs queue, which represent a batch job management system such as Slurm, IBM LSF, or Torque. With proper configuration (again, see host configuration for details), you will be able to submit your tasks to a cluster system as cluster jobs. The cluster system can be a localhost if you are submitting tasks on the headnode of a cluster system or a remote host (if you are submitting tasks remotely.
For example, with a host configuration similar to
hosts:
htc:
address: htc_cluster.mdanderson.edu
description: HTC cluster (PBS)
queue_type: pbs
status_check_interval: 60
submit_cmd: qsub {job_file}
status_cmd: qstat {job_id}
kill_cmd: qdel {job_id}
nodes: 1
cores: 4
walltime: 01:00:00
mem: 4G
task_template: |
#!/bin/bash
#PBS -N {job_name}
#PBS -l nodes={nodes}:ppn={cores}
#PBS -l walltime={walltime}
#PBS -l mem={mem//10**9}GB
#PBS -o ~/.sos/tasks/{task}.out
#PBS -e ~/.sos/tasks/{task}.err
#PBS -m n
module load R
{command}
You can submit your task to the cluster system
Again, the output of the task will be synchronized to local host
Although the usage of the workflow is largely the same as the previous example, the task statement has a few options to specify the resources used by the task, as required by the cluster system. The value of these options will be used to expand a template specified in the host specification file to generate a shell script that will be created and copied to remote host. The generated shell script could be found in the -v4 output of the sos status or magic %task status
Then, instead of command
ssh host "bash --login -c sos execute c600532cd99c02c2"
as in the last example, a command like
ssh host "bash --login -c qsub ~/.sos/tasks/1fafb4489a7b4b47.sh"
was used to submit the job to the cluster system.
The task statement accepts the following options
| Option | Usage | reference |
|---|---|---|
shared |
Return variable to the substep | this tutorial |
env |
Customized environment | this tutorial |
prepend_path |
Customized $PATH |
this tutorial |
walltime |
Total walltime of task |
task template |
mem |
Memory required for task | task template |
nodes |
Number of computing nodes | task template |
cores |
Number of cores per node | task template |
workdir |
path translation and file synchronization | |
map_vars |
path translation and file synchronization | |
| ANY | Any template variable | task template |
We will discuss some options in this tutorial, and leave the rest to specific tutorials.
SoS tasks are executed externally and by default does not return any value. Similar to the shared step option (that passes step variables to the workflow), you can use shared option to pass task variables to the step in which the task is defined.
For example, the following script perform some simulations in 10 tasks and return the result by variable rng, which is then shared to the workflow by step option shared so that it can be available to the next step.
Also similar to step option shared, task option shared accepts a single variable (e.g. rng), a sequence of variables (e.g. ('rng', 'sum')), a dictionary of variable derived from an expression (e.g. {'result': 'float(open(output).read())'}, or sequences of names and variables. In the dictionary case, the values of the dictionary should be an expression (string), that will be evaluated upon the completion of the task, and assign to the specified variable.
Please refer to sharing variables across steps (step and task option shared and target sos_variable) for more details on variable sharing.
Option prepend_path
Option prepend_path prepend specified paths before $PATH before the task is executed. It provides a quick method to fix $PATH on a specific remote host.
task: prepend_path='/path/to/mycommand'
run:
mycommand
If you have found yourself using this option a lot for a remote host, consider adding the paths to the task_template with commands such as
export PATH=/path/to/mycommand:$PATH
or using host-specific methods to set up environment properly, e.g.
module load R/3.4.4