After I announced the release of SoS Notebook as a third-party multi-language kernel for Jupyter, I was asked repeatedly (e.g. On HackerNews, AzureNotebooks, and in reviews to our manuscript) the following question:
Why did not you use an existing multi-language notebooks (e.g. Apache Zeppelin and BeakerX) or contribute a multi-language feature to the core of Jupyter or JupyterLab?
There were several technical (e.g. architecture of the current Jupyter core not suitable for multi-language support) and practical (e.g. JupyterLab was too unstable enough to work with) reasons for the decision, but the biggest reason was our vision to create a multi-language working environment backed by a workflow engine, which was too radical and too ambitious for the Jupyter core so we had to develop SoS Notebook as a Jupyter kernel for our SoS workflow engine.
Why notebook environments are limited
Jupyter Notebooks, or notebook environments in generally, or any data analysis IDEs are limited in their abilities to analyze big data. This is a difficult claim to make because there are many powerful IDEs, even big data IDEs, and there are many ways to explore even analyze big data interactively, but the basic facts are that
- It is intolerable to wait more than 5 minutes for a job to complete in an interactive data analysis environment
- However powerful your machine is, a notebook environment is limited if it can only execute scripts on one machine
So basically an interactive environment is good at prototyping and developing of data analysis steps, not at large-scale data processing. An IDE can be used to analyze small datasets or analyze large datasets occasionally, but analyzing a large amount of data should be performed on much larger (e.g. cluster) systems with assistance from pipeline systems.
Why “pipelineitis is a nasty disease”?
Everyone knows how powerful pipelines can be and awsome pipelines lists more than 100 scientific pipeline systems. However, allow me to quote Loman and Watson, 2013, Nat Biotechnol for this point:
Pipelineitis is a nasty disease
A pipeline is a series of steps, or software tools, run in sequence according to a predefined plan. Pipelines are great for running exactly the same set of steps in a repetitive fashion, and for sharing protocols with others, but they force you into a rigid way of thinking and can decrease creativity.
Warning: don’t pipeline too early. Get a method working before you turn it into a pipeline. And even then, does it need to be a pipeline? Have you saved time? Is your pipeline really of use to others? If those steps are only ever going to be run by you, then a simple script will suffice and any attempts at pipelining will simply waste time. Similarly, if those steps will only ever be run once, just run them once, document the fact you did so and move on.
The problem with all these pipeline systems is that they require you to leave your familiar data analysis environment to “program” pipelines using a different environment, description language, or even a rigirous programming language, so whereas they are powerful and friendly to workflow users, they are rarely friendly to workflow writers. The status quo is so confusing to users to a point that people are asking questions such as Does anyone use CWL? Does it actually help you get work done? My answer to this question is that workflows are counter-productive if they require you to use another environment even language.
A big hurdle from interactive to batch data analysis
So we have two sets of very nice tools but there is a big hurdle to apply scripts developed interactively to larger datasets because of the need to re-engineer the entire data analysis to a workflow using another environment or language.

How SoS solves the transition problem
There are three figures on the SoS Homepage, the first showcases the multi-language features of SoS Notebook, the third shows a DAG of a SoS workflow, the second demonstrates smooth transition from interactive data analysis to batch data processing workflow, with the following steps:
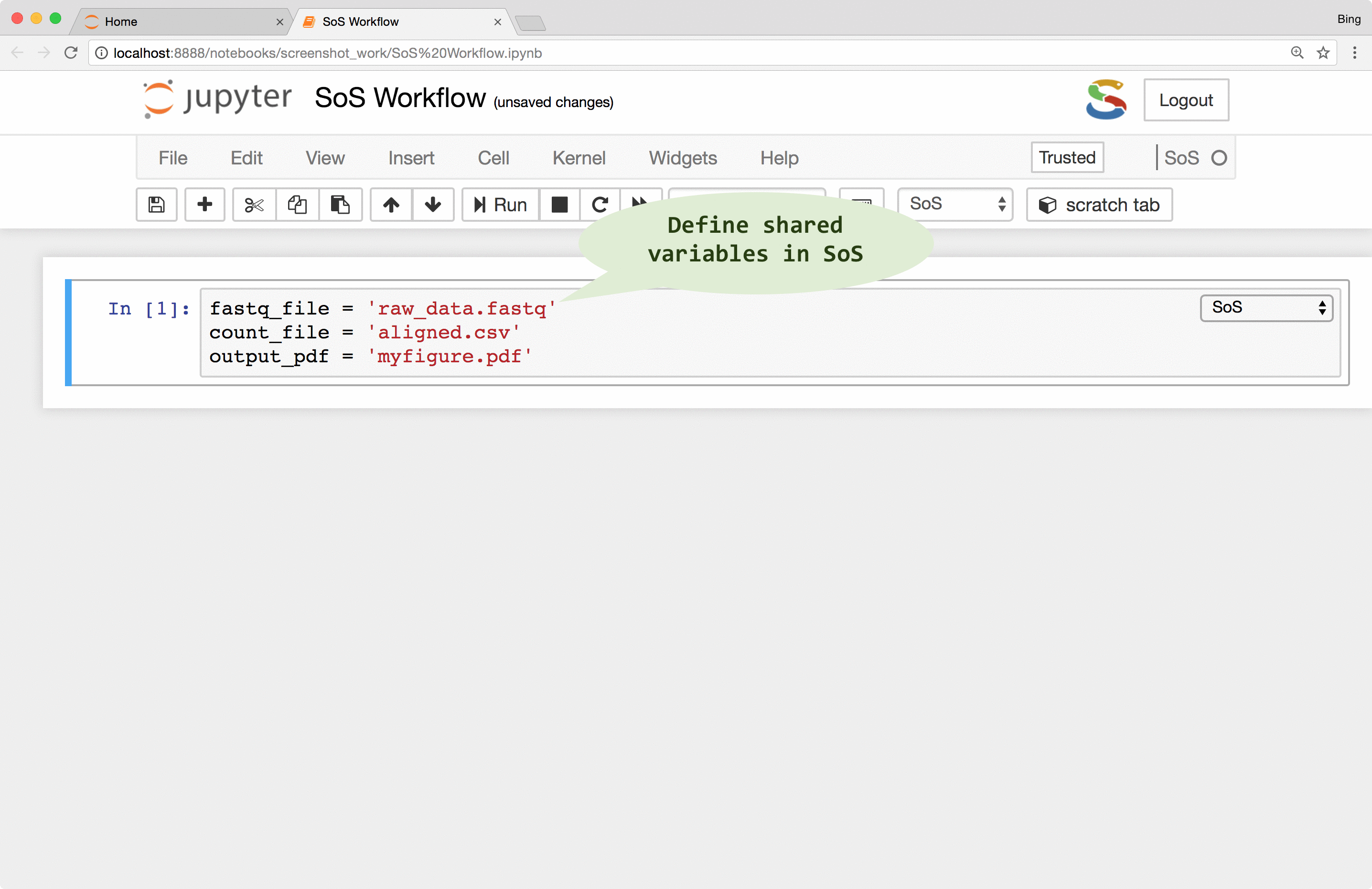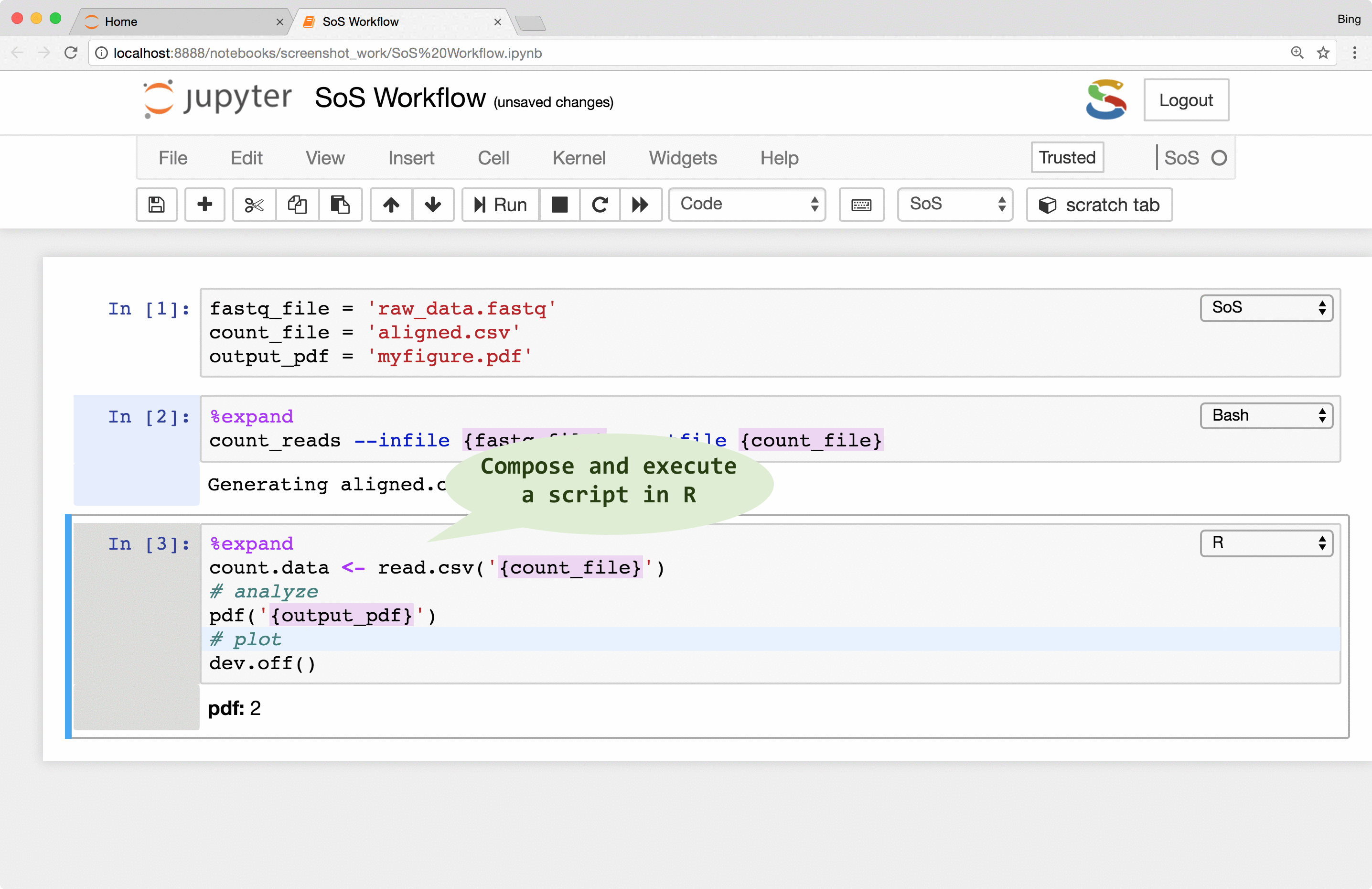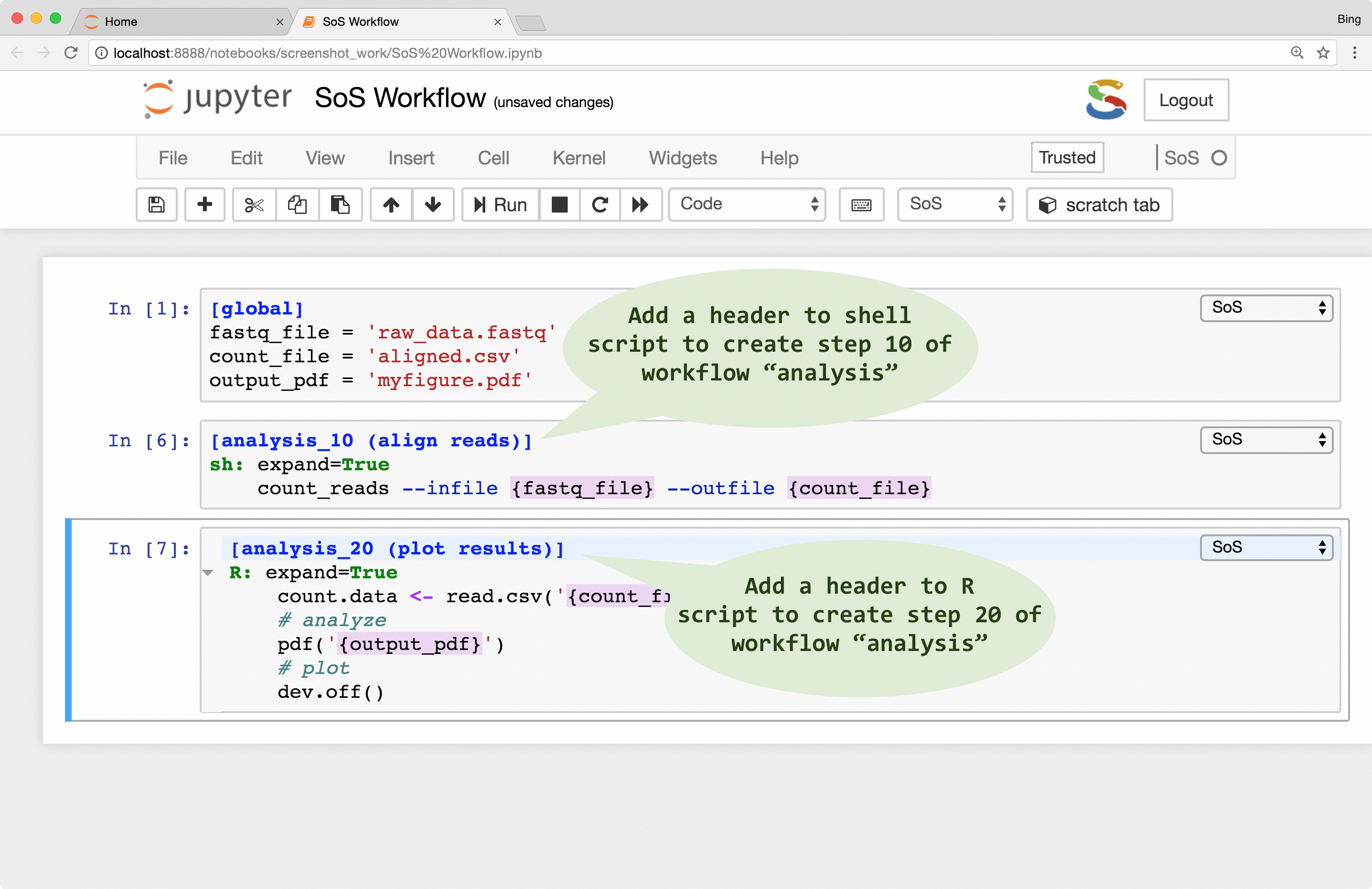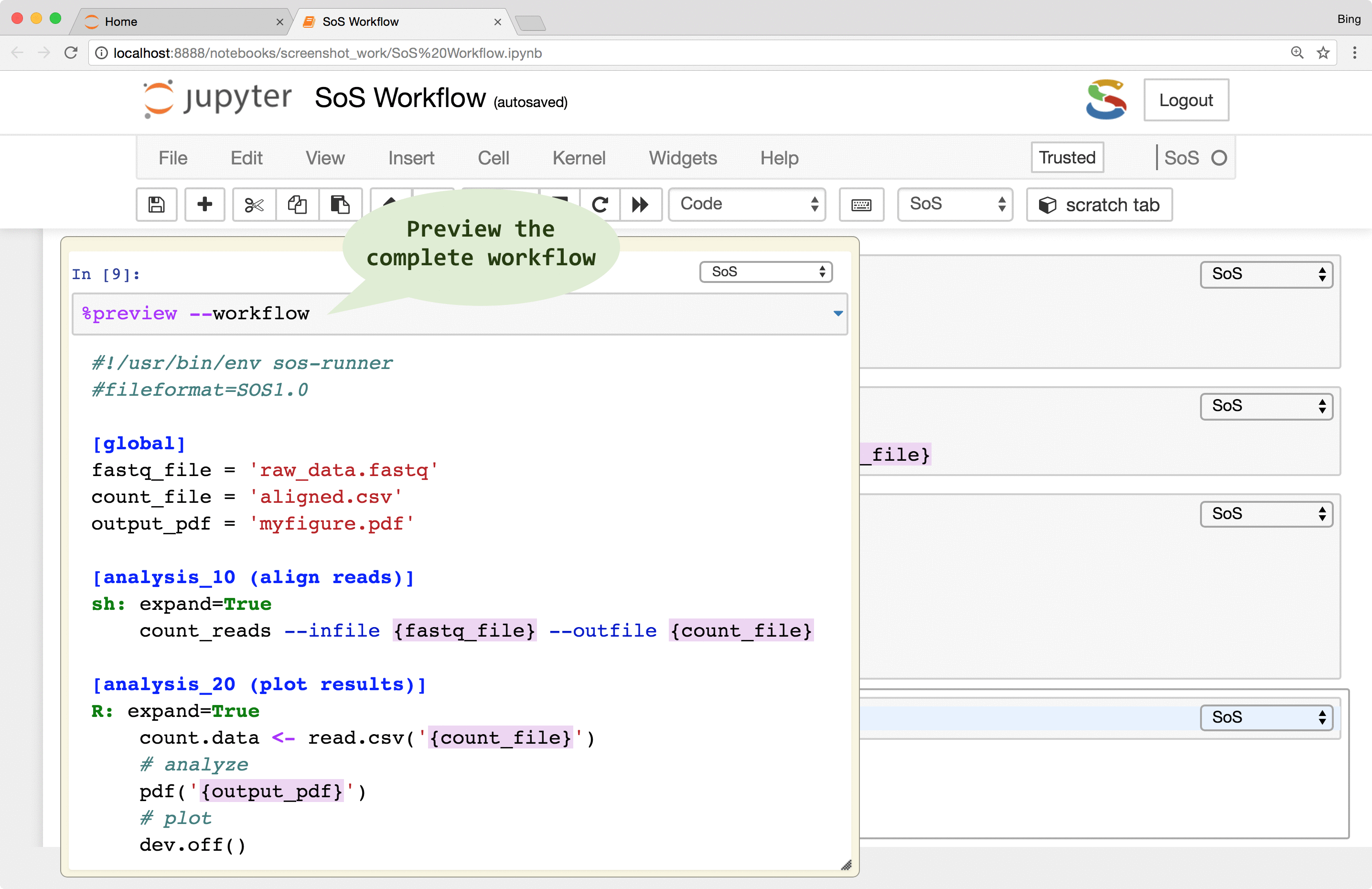
- Analyze data interactively using multiple languages (with data exchange, line-by-line execution etc).
- Convert scripts in subkernels to workflow steps in SoS Notebook with minimal syntax change (simply change the cell kernel to SoS and add an action name).
- Annotate steps with execution control directives by adding
input,output,depends,taskdirectives and section headers) to create workflows to analyze big data on local or remote systems (e.g. a cluster).
The SoS workflow engine has many features and deserves a separate post but the fact that you can use SoS inside SoS Notebook has already provided several advantages:
- SoS Notebook provides an interactive multi-language environment to develop and debug your workflow.
- The Jupyter notebook format allows you to annotate workflows with markdown cells (tables, figures etc) and allows you to keep (sample) results along with the workflow.
The following video gives more details on how to use the SoS workflow engine within SoS Notebook:
Summary
The combination of SoS Notebook with the SoS workflow engine provides a smooth transition and a single environment for both interactive and batch data analysis. The transition is designed to be as smooth as pososible by
- Allowing interactive development of scripts in any language in SoS Notebook,
- Using SoS syntaxes (e.g.
%expandmagic to interpolate scripts) in SoS Notebook, - Allowing interactive execution of SoS workflows in SoS Notebook, and
- Ability to execute SoS Notebooks from command line.
This powerful marriage between a multi-language notebook and a workflow engine allows you to grow your data analysis with more and more flexibility and ability to handle larger and larger datasets. Depending on the scale and complexity of your project, you can stop at any stage of “pipelining” your analysis and there is no need to start from scratch if you ever need to apply your analysis to larger datasets. The ability to include the entire data anlysis with descriptions and results in a single notebook makes it easy to share data analysis with others and to reproduce prior data analysis, making SoS Notebook a powerful environment for reproducible data analysis.
More details of SoS and SoS Notebook can be found at the SoS website where you can find tons of documentations, tutorials, examples, and youtube videos. Please test SoS Notebook and send your feedback and/or bug reports to our github issue tracker. If you find SoS Notebook useful, please support the project by starring the SoS and SoS Notebook github projects, or spreading the word with twitter.